PROZESSAUTOMATISIERUNG & DIGITALISIERUNG

Künstliche Intelligenz definiert visuelle Qualitätskontrolle neu
Fertigungs- und Herstellungsprozesse der pharmazeutischen Industrie unterliegen strengen regulatorischen Rahmenbedingungen um maximale Qualität, Produkt- und Patientensicherheit zu gewährleisten. Hierunter fällt auch eine Qualitätsprüfung nach der Produktabfüllung in Primärpackmittel, wie beispielsweise Spritzen, Fläschchen oder Ampullen, um mögliche Verunreinigungen, Produktdefekte oder Kontamination zu erkennen. Jedes Produkt wird diese Kontrolle unterzogen – man spricht in diesem Zusammenhang von einer 100-prozentigen Kontrolle.
Status Quo - Visuelle Produktkontrolle in der pharmazeutischen Industrie
Heutige Mechanismen zur Qualitätsprüfung umfassen die manuelle Prüfung eines jeden Produktes durch den Menschen, die halbautomatische Prüfung durch maschinelle Unterstützung des Menschen in der Inspektionsaufgabe, sowie die vollautomatische Inspektion, bei der die Maschine die komplette Inspektionsaufgabe übernimmt. Bei Letzterem werden alle Produkte durch die Maschine gefahren, eine Anzahl von Kameras schießt von jedem Produkt Bilder, die in Echtzeit in der Software der Maschine ausgewertet werden und zu einer Produktentscheidung führen.
Die Bildauswertung erfolgt heutzutage überwiegend durch klassische, regelbasierte Methoden wie Grauwert-Analysen. Dies führt zu technischen Limitierungen, insbesondere im Falle der Inspektion von Produkten, bei denen die triviale Zuordnung zu „Gut-“ oder „Schlechtprodukt“ nicht möglich ist. Eine hohe Fehlauswurfrate, also der fehlerhafte Auswurf von „Gutprodukten“, ist die Folge. Aus diesem Grund schließt sich in der Regel für alle ausgeworfenen Produkte der automatisierten Primärinspektion ein manueller Zweitabgleich an, um die guten von den wirklich schlechten Produkten zu trennen. Dieser zeit- und ressourcenintensive Prozess, basierend auf technischer Limitierung gängiger Inspektionssysteme, bedingt Kosten im einstelligen Millionenbereich für pharmazeutische Unternehmen. Diese können vermieden werden, wenn das menschliche Fachwissen im Bezug zur Inspektion der vollautomatischen Anlage zugänglich gemacht wird.

Problemlöser: Maschinelles Lernen
Für die Lösung des vorig genannten Problems sind lernende Systeme, da diese das menschliche Fachwissen aufnehmen und in einer technischen Struktur abbilden können. Im Bereich des maschinellen Lernens unterscheidet man zwischen „Supervised Learning“ Methoden (dt. bewachtes Lernen) und „Unsupervised Learning“ Methoden (dt. unbewachtes Lernen). Der Unterschied dieser beiden Methoden liegt in dem zugrundeliegenden Prinzip des Lernens.
Im unbewachten Lernen werden Datensätze vorgelegt und das lernende System versucht, Muster, Gruppierungen oder ähnliche Strukturen innerhalb dieser zu erkennen. Da die Datensätze vorher nicht aufwändig klassifiziert wurden, erhält das System keine „Belohnung“ für erlernte Inhalte, sodass der Prozess des aktiven Lernens schwierig zu beeinflussen ist. Das System lernt anhand von Beobachtung.
Im überwachten Lernen hingegen werden die Datensätze vor dem Lernprozess klassifiziert, d.h. relevante Informationen über die Daten liegen vor. Im Lernprozess werden diese Daten fortlaufend verwendet, um dem Lernsystem „Belohnungen“ auszusprechen bei korrekt erlernten Inhalten. Durch diesen Sachverhalt kann das aktive Lernen gesteuert werden. Es ist somit die prädestinierte Variante für den Bereich der visuellen Inspektion. Das System lernt, Entscheidungen aufgrund von vorklassifizierten Kamerabildern zu treffen. Diese Vorklassifizierung der Bilder wird von Inspektionsspezialisten durchgeführt. Insbesondere bei schwierig zu inspizierenden Produkten bringt dieser technologische Ansatz signifikante Vorteile, da er auf der Einschätzung und dem Wissen der menschlichen Inspektionsspezialisten beruht.
Auch wenn die mathematischen Grundlagen von lernenden Systemen schon über viele Jahre bekannt sind, so ist der industrielle Einsatz nur durch die Errungenschaften im Bereich der Mikroelektronik und dem immensen Anstieg der Verarbeitungsleistungen zu verdanken.


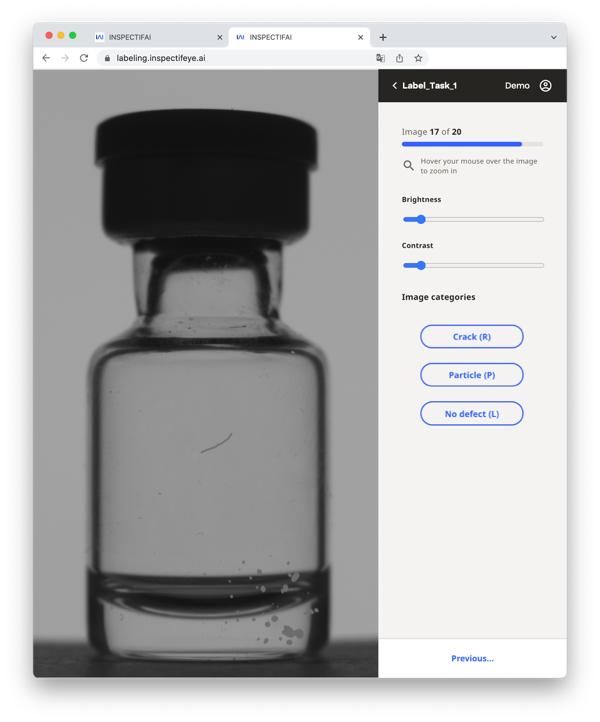
Nach der Klassifizierung der relevanten Bildmengen kann das Training des neuronalen Netzes beginnen. Hierzu werden die Bildmengen in Submengen unterteilt. Das Trainingsdatenset wird im Trainingsprozess zur Ausbildung von Knotengewichtungen, Anzahl der Ebenen, etc. verwendet. In diesem Prozessschritt erlernt das Modell Muster und Bildcharakteristiken, die schlussendlich zur Entscheidung des neuronalen Netzes führen. Mittels dem statistisch unabhängigen Testdatenset werden dem neuronalen Netz zuvor ungesehene Bilder gezeigt und deren Abbildungs- und Klassifizierungstreue geprüft. Ziel ist, ein Modell zu erhalten, das aufgrund der richtigen Bildcharakteristiken die richtige Entscheidung trifft. Hierzu existieren neben den Parametern des Trainings- und Testset-Aufteilung noch eine Vielzahl weiterer Parameter, die einen hyperdimensionalen Parameterraum aufspannen.
Daraus folgt auch, dass nicht nur ein Modelltraining durchgeführt wird, sondern eine Vielzahl. Das Wissen und die iterative Arbeit der Datenexperten bestehend aus: Modelltraining, tiefgründiger Modell- und Datenanalyse sowie die Ableitung der nächsten Optimierungsschritte. Durch dieses Wissen wird die Modellentwicklung gesteuert und führt zu einem hochqualitativen Modell, dass die gestellten Anforderungen erfüllt. In diesem Sinne fungieren das Modelltraining auch als Qualitätssicherung. Werden beispielsweise fehlerhaft klassifizierte Bilddaten zum Modelltraining verwendet, wird die daraus resultierende Modellschwäche von Datenexperten erkannt und durch eine Re-klassifizierung behoben.
Erfüllt das Modell alle Anforderungen hinsichtlich der Klassifizierungsgüte, wird der Modellstand versioniert und auf das Edge Device aufgespielt. Aufgrund regulatorischer Randbedingungen bezüglich der Qualitätssicherung und der anstehenden Qualifizierung der Maschinenperformance ist es nicht möglich, dass sich das neuronale Netz im laufenden Inspektionsbetrieb weiterhin verbessert.
Durch diesen technischen Ansatz wird das Wissen des Menschen, das durch die aktive Klassifizierungsaufgabe dokumentiert wurde, in eine technische Struktur gebunden und der Inspektionsmaschine zugänglich gemacht. Eine bessere Inspektionsentscheidung im laufenden Betrieb bei minimaler Fehlauswurfrate ist die Folge.
Ein Blick in die Zukunft – Potentiale und Herausforderungen
Perspektivisch hat die Verwendung von lernenden Systemen in der visuellen Sichtprüfung über oben beschriebenes Szenario hinaus großes Potential. Zum einen lässt sich das „gebundene Wissen“ in Form von neuronalen Netzen sehr gut teilen. Wird die Inspektion eines Produktes nicht nur an einem Standort und an einer Maschine, sondern an mehreren Maschinen durchgeführt, können die neuronalen Netze auch mehrfach verwendet werden und der Aufwand zur Erstellung des Modells verringert sich drastisch.
Darüber hinaus besteht die Möglichkeit, ein neuronales Netz, das für ein spezifisches pharmazeutisches Produkt entwickelt wurde, für ein weiteres, physikalisch sehr ähnliches Produkt zu verwenden. Dieser „Transfer“ gelingt umso besser, je ähnlicher die Definition von Gut- und Schlechtprodukt der beiden Produkte ist. Mit geringem Aufwand und geringer Bildmenge kann dem Modell zusätzliches Wissen in Form eines neuen Trainings vermittelt werden. Dies führt zu einem Modell, das auf Basis des Wissens über viele Produkte eine vertrauenswürdige Entscheidung für Neuprodukte trifft.
Für die visuelle Inspektionsaufgabe stellt dies eine Revolution dar, da Konfigurationsaufwände von Visionssystemen miniert werden bei gleichzeitiger Leistungsverbesserung und hohem Skalierungspotential.

